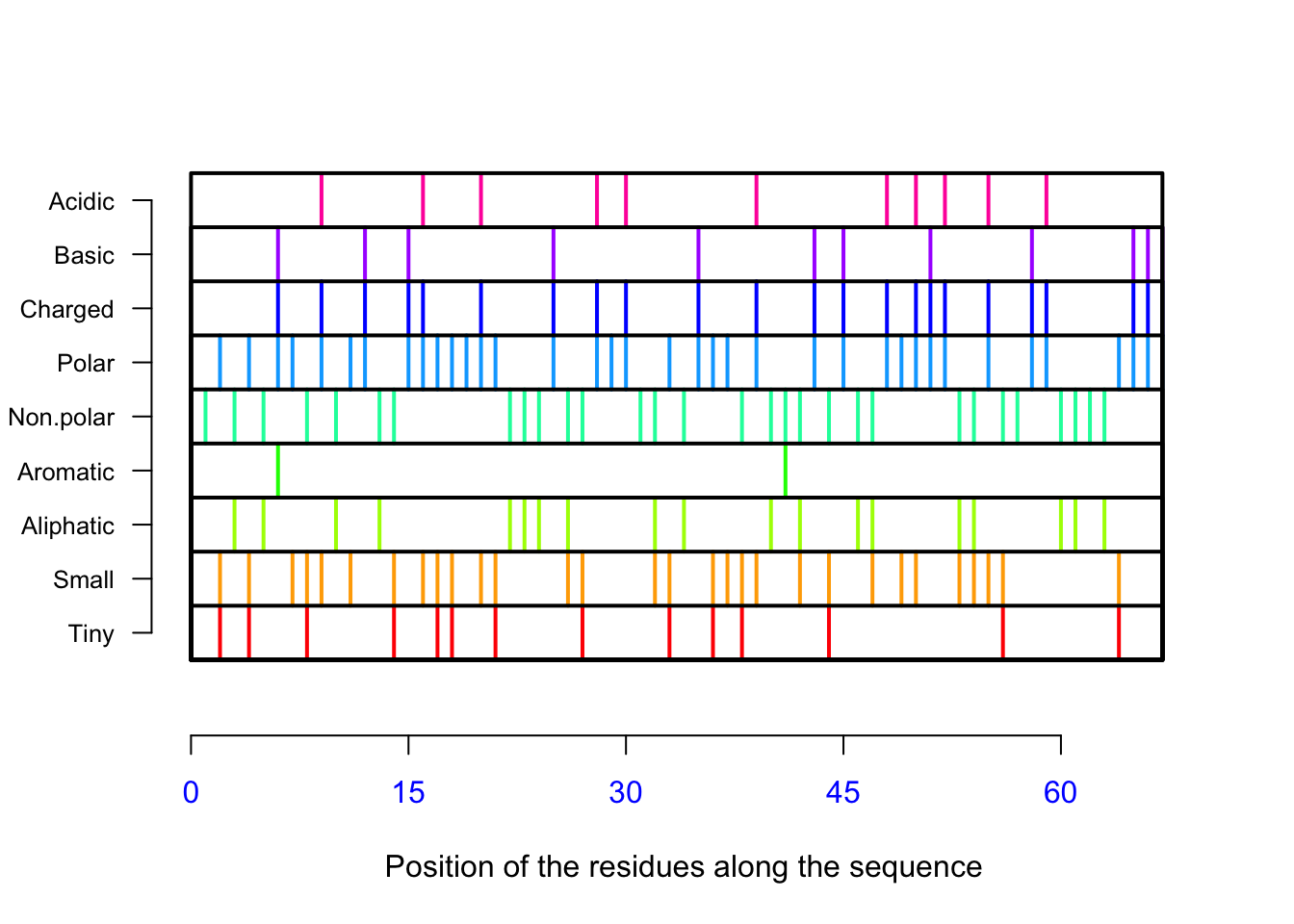
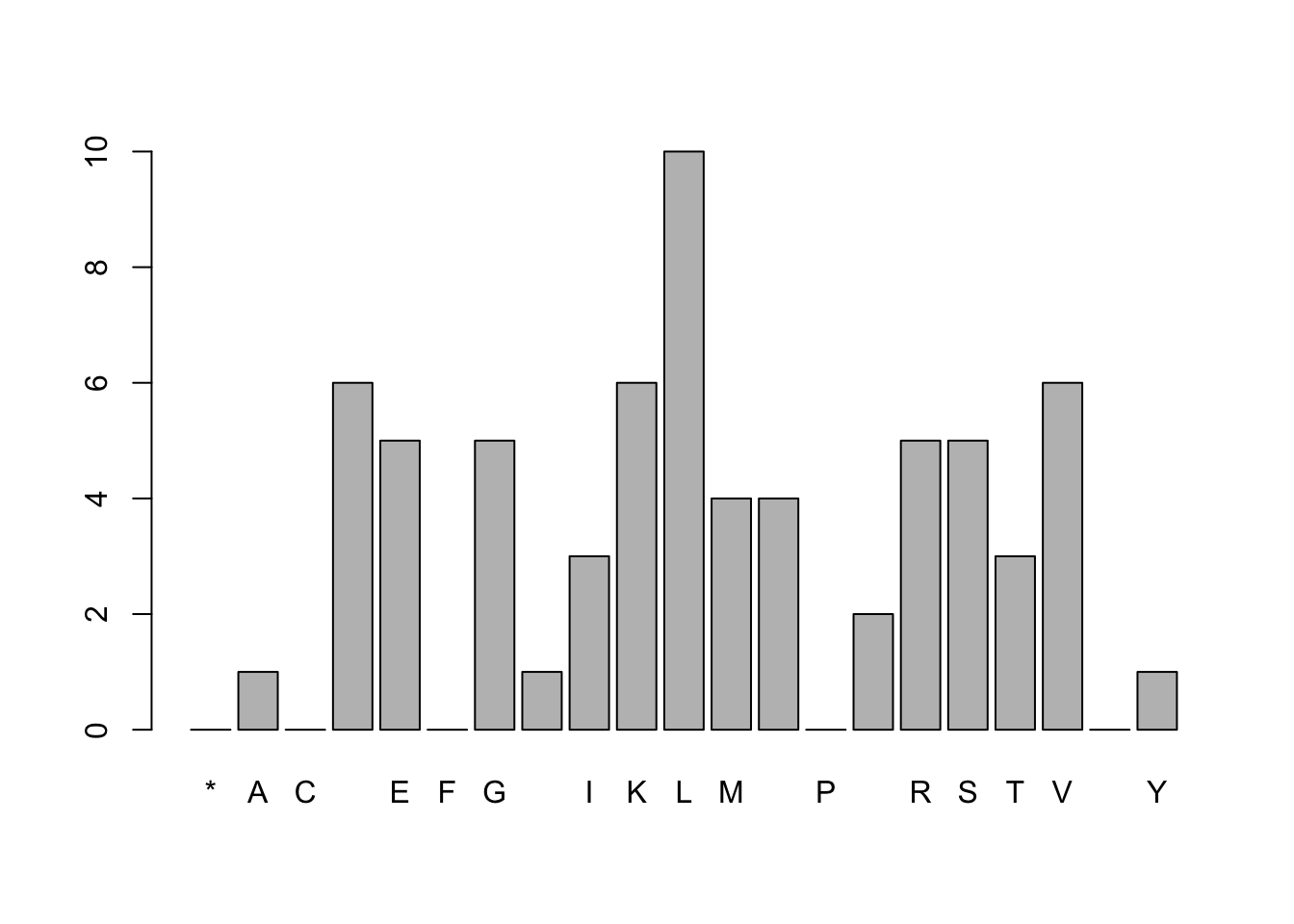
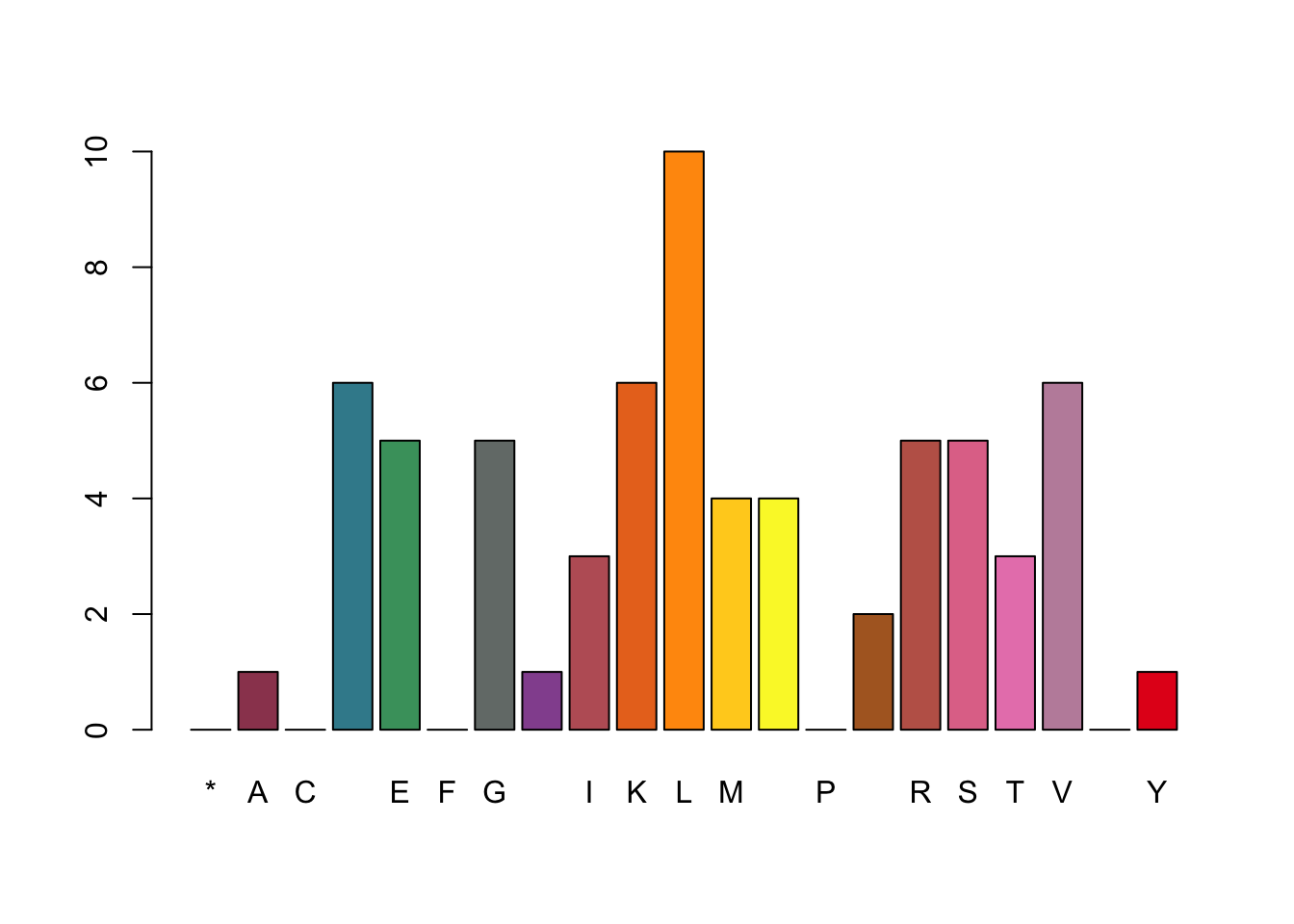
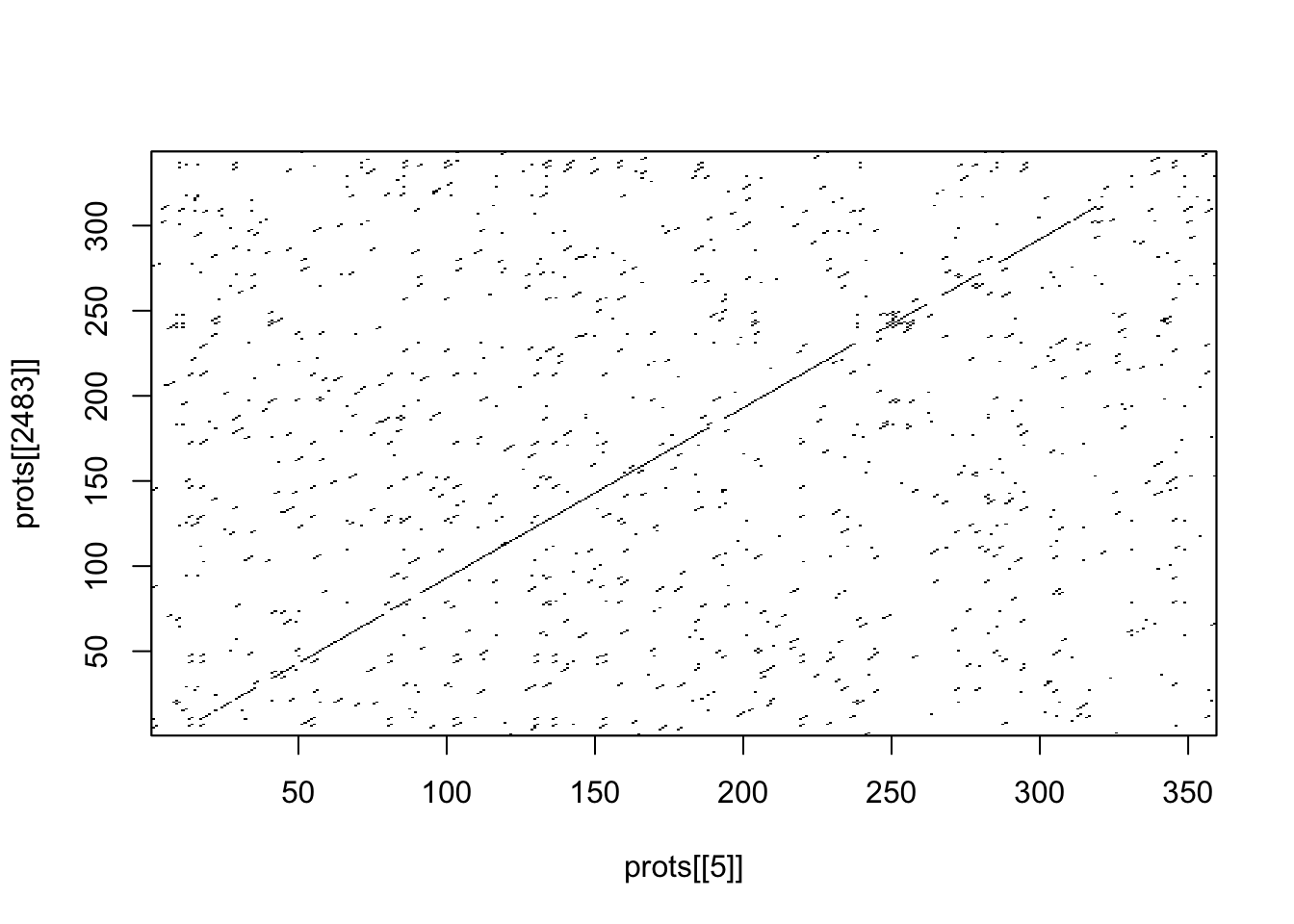
#read the text file with readLines()
proteome <- readLines("data/HER1410.fasta")
#number of sequences in the multifasta using grep
length(grep(proteome, pattern=">"))[1] 5807#extract recombinases
grep("recombinase", proteome,value=TRUE) [1] ">QKO37045.1 recombinase RecA (plasmid) [Bacillus thuringiensis]"
[2] ">QKO36998.1 recombinase family protein (plasmid) [Bacillus thuringiensis]"
[3] ">QKO36701.1 DDE-type integrase/transposase/recombinase (plasmid) [Bacillus thuringiensis]"
[4] ">QKO36696.1 tyrosine recombinase XerS (plasmid) [Bacillus thuringiensis]"
[5] ">QKO36060.1 tyrosine-type recombinase/integrase [Bacillus thuringiensis]"
[6] ">QKO36057.1 tyrosine-type recombinase/integrase [Bacillus thuringiensis]"
[7] ">QKO35589.1 recombinase family protein [Bacillus thuringiensis]"
[8] ">QKO35551.1 tyrosine-type recombinase/integrase [Bacillus thuringiensis]"
[9] ">QKO35280.1 recombinase family protein [Bacillus thuringiensis]"
[10] ">QKO34873.1 site-specific tyrosine recombinase XerD [Bacillus thuringiensis]"
[11] ">QKO34618.1 tyrosine recombinase XerC [Bacillus thuringiensis]"
[12] ">QKO34567.1 recombinase RecA [Bacillus thuringiensis]"
[13] ">QKO34482.1 recombinase family protein [Bacillus thuringiensis]"
[14] ">QKO32507.1 recombinase RecQ [Bacillus thuringiensis]"
[15] ">QKO32484.1 tyrosine-type recombinase/integrase [Bacillus thuringiensis]" #enzymes (aka "-ases")
head(grep("ase", proteome,value=TRUE))[1] ">QKO37046.1 helicase DnaB (plasmid) [Bacillus x1]"
[2] ">QKO37045.1 recombinase RecA (plasmid) [Bacillus thuringiensis]"
[3] ">QKO37043.1 IS3 family transposase (plasmid) [Bacillus thuringiensis]"
[4] ">QKO37040.1 serine acetyltransferase (plasmid) [Bacillus thuringiensis]"
[5] ">QKO37039.1 O-antigen ligase family protein (plasmid) [Bacillus thuringiensis]"
[6] ">QKO37026.1 HK97 family phage prohead protease (plasmid) [Bacillus thuringiensis]"head(grep("ase", proteome,value=TRUE,ignore.case=TRUE)) #lower- & uppercase[1] ">QKO37046.1 helicase DnaB (plasmid) [Bacillus x1]"
[2] ">QKO37045.1 recombinase RecA (plasmid) [Bacillus thuringiensis]"
[3] ">QKO37043.1 IS3 family transposase (plasmid) [Bacillus thuringiensis]"
[4] ">QKO37040.1 serine acetyltransferase (plasmid) [Bacillus thuringiensis]"
[5] ">QKO37039.1 O-antigen ligase family protein (plasmid) [Bacillus thuringiensis]"
[6] "SMSCDIDPTEIITRLTPLGTRIESKNEGATDASEARLTIESVNNGVPYIDHPSGIKEFGIQGKSITWDDV" #extract names
fastanames <- proteome[grep(proteome, pattern=">")] #extract the headers of all the sequences
names_ase <- fastanames[grep(fastanames, pattern="ase")]